KubeMQ Bridges for Edge Computing
Struggling to communicate between your edge sources and the home cloud? Messaging could be the solution.
Introduction
For years, companies have been moving to the cloud. With the ubiquity of internet-connected devices, it seems only natural to rely on cloud-based services for the majority of applications today. However, the rise of edge computing has demonstrated that there is also a need for hyper-local, distributed computing which can offer latencies and resilience that the cloud cannot match. With these benefits come ever-increasing complexity both in terms of individual application development as well as overall infrastructure management.
In this article, we’ll take a look at the unique benefits and challenges of edge computing, as well as how a lightweight, Kubernetes-based messaging queue can meet those challenges.
Edge Computing
Edge computing can be defined as bringing data and its associated processing closer to the point of use and is a form of distributed computing. In order to understand edge computing, we first need to understand the limitations of cloud computing.
Limitations of the Cloud
Cloud computing has brought many advantages to modern application development. It is easier and faster than ever to spin up virtualized infrastructure from any number of IaaS providers. However, I would like to highlight two drawbacks to cloud infrastructure—latency and cost.
First, latency to your cloud can be inconsistent depending on the location and network context of your users. If your data center is in the Eastern US, users from Asia attempting to access your application could experience > 200ms latency on every request to and from your cloud. Additionally, mobile or users in remote locations will have inconsistent network connectivity. If your app depends on a constant connection to the cloud, mobile users could suffer from a degraded experience.
Cost can become an issue with cloud environments. You might think this is due to the cost of compute, and while this is certainly true, the main issue we are concerned with here is the cost of bandwidth. If your mobile device depends on sending every piece of data back to the cloud, you are incurring costs for that bandwidth both to send (from mobile device to the network) and to receive that data in your cloud.
To illustrate both latency and cost concerns, let’s consider the case of an autonomous, self-driving vehicle. What if this vehicle was a “dumb” vehicle that sent all its data to the cloud and depended on instructions to come back from the cloud in order to know whether to steer, brake, or turn? As you might imagine, such a vehicle would be heavily dependent on its network connection, and any interruption or delay would be disastrous. Additionally, the bandwidth required for such a connection would be substantial and costly.
Let’s take a look at how edge computing can address these two drawbacks.
Edge Use Cases
In edge computing, we want to reduce dependence on that network connection. In the aforementioned example of a self-driving vehicle, we can do so by making the vehicle “smart” by moving computation and processing to the vehicle itself. If the vehicle can process its own sensor data and make its own decisions about driving, then this reduces network dependence. Additionally, the latency between receiving sensor data and taking an action can be reduced beyond what would even be possible with a cloud-dependent connection.
Edge computing has relevance across a number of verticals and industries. Utility providers for compliance reasons need to collect data in remote locations, and must be able to do so regardless of the network availability in those locations.
Another example is a manufacturer who requires flexible machines which can operate without required server connectivity on the factory floor. Environmental monitoring also requires the ability to operate in remote places. The list could go on; IoT devices, point of sale, healthcare, and so on can all benefit from reduced latency and the ability to operate independently of a network connection.
Edge Considerations
When planning an edge computing-based solution, some considerations are required.
First, compute at the edge is often limited. For a variety of reasons (size, power requirements, cost) edge devices typically have a limited amount of computing power and bandwidth available to them. As such, any edge computing solution must be both lightweight and able to handle interruptions in network connectivity.
Second, as the amount of compute occurring outside of your home cloud increases, the complexity of managing those edge computing environments increases as well. These edge environments are no longer simply conduits of data, but application infrastructure which must be maintained, updated, and overseen much as your home cloud needs continuing oversight.
Finally, network instability is a constant reality at the edge. This has already been mentioned but it is worth repeating. Any data transfer which happens between the edge and the cloud must have a way to handle interruptions in connectivity and potential data loss.
While each of these considerations requires attention, that doesn’t mean it has to be complicated. Let’s take a look at how a combination of messaging and Kubernetes can handle each of these issues.
Messaging to Bridge the Gap
One possible solution for these challenges is the use of a Kubernetes-native messaging queue. Messaging addresses the network instability, Kubernetes aids in managing environment complexity, and now we just need to make sure the product is lightweight enough to work within limited compute environments.
We’ll use KubeMQ as our example as we consider how this type of solution meets the needs of edge computing. KubeMQ is a messaging queue designed to be Kubernetes-native from the beginning. It is written in Go and extremely lightweight (the container is < 40 MB).
Messaging when network stability is degraded
First, messaging provides a neat solution for degraded network stability. A messaging queue such as KubeMQ allows messages to be sent and delivered asynchronously. Network down? The queue will simply wait until the network is back to send messages. Bandwidth limited? The queue can be configured to batch messages together to make the most of limited bandwidth. Alternately, you can use one queue for important messages to be sent on mobile, and another queue that waits until it is on a home network.
Similarly, messaging also addresses the issue of reliability. Through features such as guaranteed delivery, it is possible to ensure that messages are neither dropped nor duplicated. This means that your app can depend on the information contained in the message that it receives.
Lightweight enough to enable flexible deployments
Second, a solution such as KubeMQ is lightweight enough to be deployed to nearly any limited compute edge environment. Traditionally, message queues are large, resource-intensive applications. Consider, for example, the latest version of IBM MQ, which at the time of writing has significant hardware requirements such as > 1.5 GB disk space and 3 GB of RAM. In contrast, KubeMQ can be spun up basically anywhere you can create a Kubernetes cluster. With solutions such as MicroK8s and K3s, you can even run KubeMQ on a Raspberry Pi.
Similarly, the flexibility of Kubernetes and KubeMQ means that the operating system is not a limiting factor. Windows, Linux, and ARM are all supported, meaning that a complex, diverse edge environment with many different types of devices and apps can all use messaging for communication.
Bridges to communicate between edge and cloud clusters
Finally, KubeMQ Bridges provides a solution for the complexity of managing all this communication. KubeMQ Bridges allows KubeMQ clusters to communicate with one another even across various networks and cloud environments.
For example, consider the case where you have many autonomous environmental sensing devices. Each of these needs to communicate back to your home cloud, but you don’t want to just blindly open up the cloud to any device which tries to access it. Through KubeMQ Bridges, each device can run its own KubeMQ cluster, which then communicates through a KubeMQ bridge to a KubeMQ cluster within the home cloud. This simplifies the process both for the devices and for the maintainer of the home cloud.
KubeMQ is lightweight enough that you can try out multiple cluster and bridge functionality on your local machine—let’s give it a spin!
Try it out! A tutorial on how to bridge between multiple KubeMQ clusters
Installation
First, we need to set up a KubeMQ account here. Once that’s done, log in and save the command that looks like this:
kubectl apply -f https://get.kubemq.io/deploy?token=<your token here>
You’ll also want to install kubemqctl, the KubeMQ command line tool. There should be instructions on your login page as well. If you’re using Windows like I am, open up an elevated PowerShell prompt and run the following:
New-Item -ItemType Directory 'C:\Program Files\kubemqctl'
Invoke-WebRequest https://github.com/kubemq-io/kubemqctl/releases/download/latest/kubemqctl.exe -OutFile 'C:\Program Files\kubemqctl\kubemqctl.exe'
\$env:Path += ';C:\Program Files\kubemqctl'
Next, we need to set up a Kubernetes cluster locally (I’m going to be using minikube) as well as the Kubernetes command-line tool, kubectl. If you don’t already have these or a suitable alternative, go ahead and install them now.
Start up your cluster (for me, that is done via minikube start). Once that completes, run kubectl get po -A and you should see something like the following:

Cluster Setup
Don’t worry about these pods, as we’ll be creating our own! Next, go ahead and clone the kubemq-bridges repository:

We’re primarily interested in the replicate example in the “examples” folder, so let’s get to that for our working folder:

First, let’s do the initial KubeMQ install. Run that command you saved from earlier.
kubectl apply -f https://get.kubemq.io/deploy?token=<your token here>
If you see an error such as no matches for kind “KubemqCluster”, just run the command a second time.
Next, let’s apply the provided deploy.yaml file via kubectl apply -f ./deploy.yaml.

This deployment command creates four KubeMQ clusters, as well as the bridge connector between them. This bridge replicates messages from cluster A to clusters B, C, and D. Setting up these four clusters on your local machine will probably take 2-3 minutes, so go get a drink (of water!) real quick.
Now that you’re back, you can check the status by running kubemqctl get clusters:

Once you have all 3’s in the ready column, make sure the connector is up as well by running kubemqctl get connectors:

Sending Messages
Now, let’s test it out! Let’s configure kubemqctl to connect to cluster A by using kubemqctl config:
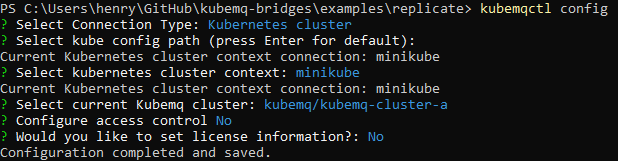
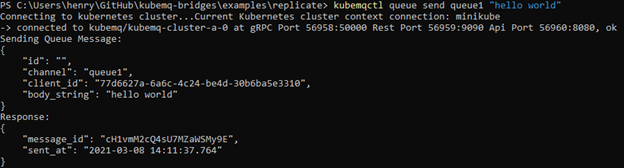
And, let’s put a message into queue1 with kubemqctl queue send queue1 "hello world". You should see something like the following:
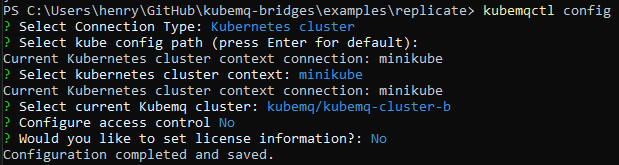
Now, let’s receive the message. Run kubemqctl config again, but point it at cluster B:
And let’s receive the message with kubemqctl queue receive queue1:
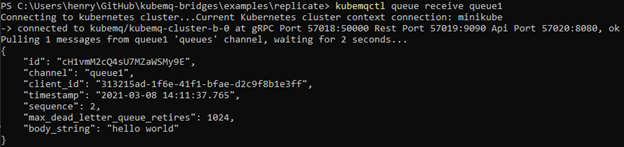
Success! You can check clusters C and D as well and receive the messages there. Or if you want to add or edit connectors of your own, try it out via a guided process by running kubemqctl manage.
Summary
In this article, we went through an introduction to edge computing, how messaging can address the complexity and limitations of edge computing, and how to set up a simple KubeMQ Bridge between four KubeMQ clusters on your local machine. An edge computing solution with KubeMQ linking your edge and home cloud has the potential to be simple, effective, and powerful.
If you have any questions or comments, please feel free to contact me at hello@henryjin.dev or check out my website at https://henryjin.dev to learn more about me. Thanks for reading!